We regularly hear about how the broadcast industry has a “skills shortage” that needs to be addressed, but it’s often not clear what this actually means in the real world. Much of the industry continues as normal without viewers noticing, but this doesn’t mean there are no underlying structural issues beneath. In particular, the move to IP, cloud and software has exposed the industry skills shortage. An understanding of IP workflows, and in particular fault-finding in the IP, software and cloud domain, is substantially more complex than in traditional workflows such as SDI.
I believe there is a large gap between the ambitions of broadcasters to move to IP/cloud, the overall direction of travel in technology, and the skillset on the ground needed to deliver. For this reason, I created the tongue-in-cheek “pyramid of incompetence” [below], a diagram showing topics in which I feel broadcasters lean too much on manufacturers instead of trying to understand these topics themselves. This was a parody of the European Broadcasting Union (EBU) “Technology Pyramid of Media Nodes”, a diagram showing vendor compliance to ST 2110 and other technical standards. Essentially it turned the pyramid on its head; usually, it’s broadcasters scrutinising vendors, but this time it’s a vendor scrutinising broadcasters.
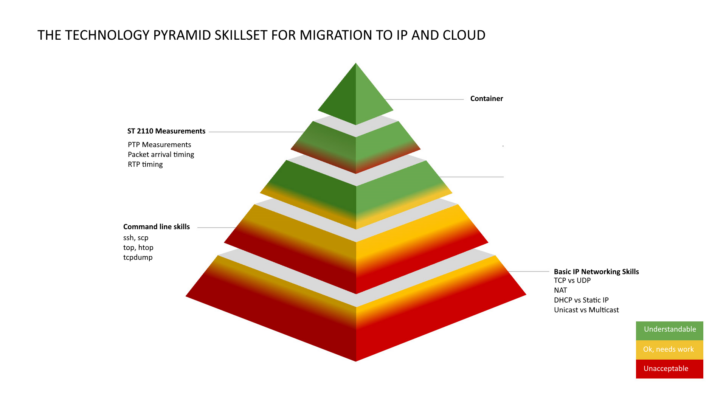
Whilst this pyramid was intended as a joke, it seems to have led to a lot of industry comment, perhaps because these industry concerns have been simmering underneath the surface, but it has been considered uncouth for vendors to make comments about their potential customers. But again, I would argue serious conversations like this are exceptionally important as the industry goes through this unprecedented transition.
System architecture and complexity in the IT-centric world far exceeds that of legacy hardware and appliance-based pipelines. In many broadcasters, the immediate reaction whenever there is an issue of any sort is to press a figurative “big red button” (where available) to switch to a backup and then immediately call up a vendor and say “it’s not working”. And to be fair, in the SDI world, this was a reasonable thing to do. If there was a problem with SDI from a device, the chances are it was the fault of that device and something the vendor needs to know about.
But IP and cloud are different, there’s a patchwork of different systems and workflows out there that require careful and methodical monitoring and fault-finding. And yet in a small, but vocal minority, fault-finding skills are non-existent and so vendors get the “it’s not working” call about a network they didn’t design and build and are expected to troubleshoot. Calling up a vendor about an IP/cloud issue and saying “it’s not working” without making any effort to fault-find is unacceptable. This forces a product manufacturer to be both an IT department and systems integrator to try and solve a fault that’s most likely unrelated to the product. Product support teams are there to solve product issues (providing recurring value to the vendor), not to run an IT department for customers that will break even at best.
One of the existential challenges many broadcasters have is to move from big-iron hardware to IP and then to cloud. But there is no “big red button” in the cloud, nor are there cables to crimp and coil. IP and cloud requires a complete change in mindset. This isn’t like the change from analogue to digital or SD to HD, it’s a complete step-change in all technological aspects of broadcasting. All the competitors to linear broadcasting, Netflix, Youtube, TikTok etc. are all cloud-native to begin with. As the pyramid shows, some broadcasters struggle with basic concepts such as TCP vs UDP or Unicast vs Multicast. There’s no chance of ever moving to the cloud if broadcasters struggle with the basics (and indeed we get lots of calls and emails about this). It’s not going to get easier as technology progresses. At Netflix they are working on world-leading research about TCP performance and network optimisation, yet in broadcast we are still struggling with the first lecture in a networking course.
It’s not all dire of course, there are many broadcasters with excellent fault-finding skills and a methodical approach to solving problems. But these often aren’t the people shouting the loudest because they are busy putting things on air.
So what’s the solution? Training and a cultural shift. Engineers on the ground should be empowered to fault-find themselves in a blame-free culture. It’s easy to just reboot a device and say “that fixed the issue”, but was it actually something more complicated in the architecture? For vendors, the current economic situation will likely put an end to the “it’s not working” calls as CFOs find it unreasonable to run loss-leading support departments, which actually function as IT departments for their clients.
One other possible option of course is for broadcasters to use managed service providers. This is especially beneficial for smaller broadcasters where a critical mass of engineering knowledge may not exist. There is a wide range of managed service providers out there covering all or just a portion of a given technical workflow in broadcasting.
This diagram was intended to spark discussion at a conference but at the same time many a true word is spoken in jest. The skills shortage, unfortunately, isn’t a joke.
This article first appeared in TVBEurope’s June/July 2023 issue.







